1.1. 개요
운영체제 - 컴퓨터 하드웨어와 컴퓨터 사용자간의 매개체 역할을 하는 시스템 소프트웨어.
주 목적 - 컴퓨터 시스템을 편리하게 이용
부수적 목적 - 컴퓨터 하드웨어를 효율적으로 관리
모든 운영체제는 관련 처리기, 메모리, 디바이스, 파일, 네트워크들과 보안 등에 최선의 방법으로 모든 자원들을 관리해야 한다.
# 운영체제는 자원관리, 할당자 라고 볼수도 있다. 컴퓨터 시스템은 하나의 문제를 해결하기 위해 필요한 자원들, 중앙처리장치 점유시간, 기억장치 공간, 파일 저장공간, 입출력장치 등을 운영한다. 운영체제는 이들 자원의 관리자로서 특정 프로그램과 사용자 간의 작업에 필요한 자원을 할당해 준다.
어떻게 할당할 것인가? 요구가 충돌되는 경우가 발생하므로 다음 문제점들의 해결이 요구된다.
- 어떤 응용 프로그램이 우선순위가 높은가
- 어떤 파일이 하드드라이브 상 가장 빠른 검색이 가능한 위치를 부여받을 것인가
- cpu 의 빠른 처리와 디스크 접근속도중 어느쪽이 더 중요한가
- 상대적으로 더 중요한 사용자의 경우 그 처리를 위한 대기시간은 최소화되는가?
# 또 다른 관점은 다양한 입출력 장치와 사용자 프로그램의 통제자로 보는 것이다.
이떄의 운영체제는 제어 프로그램으로 볼 수 있으며, 제어 프로그램은 사용자 프로그램을 통제하여 오류 또는 컴퓨터의 부적절한 사용을 방지한다는 것이다.
## 운영체제는 자원을 관리하고 할당하는 software
- kernel : 컴퓨터에서 항상 실행되는 핵심 프로그램이자 운영체제의 핵심
- system programs : 운영체제와 연관되어 있으나 커널의 일부분은 아닌 프로그램
- application programs : 그 이외 프로그램
# 운영체제의 유형
- 일괄 처리 시스템 (batch processing system)
- 다중 프로그래밍 시스템 (multiprogramming system)
- 시분할 시스템 (time-sharing system)
- 실시간 시스템 (real-time system)
- 다중 처리 시스템 (multiprocessing system)
- 개인용 컴퓨터 시스템 (personal computer system)
- 분산 처리 시스템 (distributed processing system)
- 멀티미디어 시스템
- 임베디드 시스템
# 운영체제에 대한 관점
## 자원 관리자 관점
운영체제는 컴퓨터 시스템을 구성하는 각종의 자원관리자로 볼 수 있다. 시스템 자원에는 프로세서, 기억장치, 각종 장치, 프로그램이나 데이터와 같은 정보 등이 있다.
운영체제는 각 자원의 상태를 추적, 저장해야 하고, 어떤 프로세스에게 언제 어떤 자원을 할당할 것인지 결정 후, 그것을 할당하고 회수해야 한다.
각 자원에 대한 관리자는 공통적으로 아래 과정을 거친다
자원 상태 추적, 저장 > 어떤 프로세스가 언제 어떤 자원을 얼마나 사용할것인지 결정하기 위한 정책 수립 > 자원 할당 > 자원 회수
1. 프로세스(cpu의 처리단위) 관리 기능
트래픽 제어기(traffic controller) - cpu와 process의 상태를 추적, 저장하는 프로그램
job scheduler - 어떤 작업에게 어떤 프로세서를 사용하도록 할 것인지 결정, submit 된 모든 작업중 하나를 선택하여 그 작업이 필요로 하는 자원을 할당한다.
process scheduler - 어떤 프로세스가 언제 얼마나 중앙처리장치를 차지할 것인지를 결정 (다중 프로그래밍 시스템의 경우)
dispatcher - 필요한 하드웨어 레지스터를 setup 함으로서 프로세스에게 중앙처리장치를 할당, 프로세스가 수행을 마치거나 허용된 사용시간 초과시 중앙처리장치 회수
2. 기억장치 관리 기능
기억장치의 상태를 추적,저장.
만약 다중 프로그래밍 환경 하에서라면 어떤 프로세스에게 언제, 얼마의 기억장치를 할당할 것인지를 결정
프로세스가 기억장치를 요구시 결정한 내용에 따라 할당, 필요로 하지 않게되면 회수
3. device 관리 기능
I/O traffic controller - 채널 등 제어장치 및 입출력장치와 같은 각종 장치의 상태 추적, 저장
I/O scheduling - 장치 할당에 어떤 방법이 효율적인지 결정, 이때 만약 장치가 공유되는 것이라면 어떤 프로세스가 이 자원을 얼마나 사용할 것인지를 결정
해당 장치를 할당, 입출력 동작 시작, 입출력 종료시 자동적으로 자원 회수
4. 정보 관리 기능
file system - 정보의 위치, 사용 여부 및 상태 등을 추적, 관리한다.
어떤 작업에게 정보 자원을 사용하도록 할 것인지 결정한다. 정보보호를 위한 대책을 수립하고 access 루틴을 제시. 정보 자원을 할당하거나 회수.
## 프로세스 관점
운영체제는 하나의 작업이 제시되어 완료될때까지 하나의 프로세스에 대해 그 상태를 변환시키고 관리할 책임이 있다.
여러 작업이 수행될 경우 cpu가 처리할 수 있는 것은 어느 한 시점에서 볼때 오직 하나의 프로세스 뿐이다. 선택받지 못한 프로세스는 자신의 위상에 따라 상태를 변환시켜야 한다. 만약 실행중의 프로세스가 입출력이 완료되기를 기다려야 한다면 그 프로세스는 입출력 완료 시점까지 대기 상태의 프로세스로 변환되어야 한다.
## 계층 구조 관점
자원 관리 루틴이 어떻게 수행되고, 이 루틴들이 상호간에 어디에 논리적으로 위치하는가?
과거에 존재했던 대부분의 운영체제는 하나의 큰 프로그램으로 구성되었다. 그러나 시스템이 보다 커지고 복잡해짐에 따라 맹목적인 접근 방식으로는 더 이상 운영체제를 관리할 수 없게 되었다.
시스템 모듈(운영체제) 에서 필요로 하는 주된 기능은 내부적 확장 기계로, 그 이외의 모듈은 외부적 확장 기계로 분류된다.
내용생략
# 입출력 프로그래밍
cpu 내에서 모든 연산은 제어장치의 통제에 의해 동기화되어 작동한다. 그러나 대부분의 컴퓨터에 있어서 입출력은 중앙처리장치와 비동기적(asynchronous) 으로 수행되는데. 이 의미는 cpu와 I/O에 대한 작동이 독립적이며, 수행상의 시간관계 규정이 없이 병행적으로 수행됨을 의미한다.
입출력 장치는 cpu와 비교할때 데이터 처리시간이 일정하지 않다. 처리속도의 차이와 불확실덩 때문에 상호작용에 주의가 필요하며, 입출력 프로그래밍이 필요하다.
## BIOS(basic input/output system)
컴퓨터가 ROM에서 얻는 정보를 BIOS 라고 부른다. 부트 프로세스를 실행시키는 명령어들을 포함하고 있으며, 이러한 형태의 컴퓨터칩에 저장된 명령어를 firmware라고 부른다.
## boot process
부트 절차는 이러하다.
1. 컴퓨터 가동을 위해 파워버튼 누름, 부트 로더가 초기화됨
2. POST(Power-On Self-Test) 수행 시작
3. 다른 BIOS들이 가동을 위해 초기화 됨
4. 유저는 필요에 따라 BIOS 접근을 위한 비밀키 입력을 요구받음
5. 간단한 메모리 테스트가 수행, 여러 파라미터들이 세트됨
6. 플러그앤 플레이 디바이스들이 초기화
7. DMA(direct memory access) 채널을 위한 자원들과 IRQ(interrupt request)가 할당됨
8. 부트 디바이스들이 정해지고 초기화 됨
9. OS가 초기화 됨
## POST(Power-On Self-Test)
성공적인 부팅, 적정 수행의 확인을 위해 필요 하드웨어에 행하는 테스트
BIOS의 완벽한 보전 확인
주기억장치의 위치 결정과 확인 및 크기(size) 결정
시스템버스와 시스템 디바이스 결정 및 시작
요구되는 다른 BIOS들의 시작 허용(비디오, 그래픽카드 등)
사용자에게 BIOS 시스템 구성 페이지에 접근할 수 있는 권한 부여
부트 디바이스 위치 및 부트 파일을 가진 디바이스 찾기
운영체제에 의해 요구되는 그 외 작동준비(setup)관련 작업의 수행
## buffering
입출력장치나 보조기억장치는 기계적 요인으로 cpu와 비교시 느리게 작동한다. 이 느린 속도를 보완하는 방법으로 버퍼링이 있다.
버퍼링은 cpu와 I/O를 항상 바쁘게 하고자 하는 것으로, 한 레코드가 읽혀 중앙처리장치가 그것에 대한 연산을 시작함과 동시에 입력장치가 그 다음에 필요한 레코드를 미리 읽어서 주기억장치에 저장함으로서, 중앙처리장치가 필요한 레코드를 기다리는 일이 없도록 하는 것이다.
buffer - 미리 읽혀진 레코드들이 존재하는 주기억장치의 일부
출력에 대해서도 이와 유사한 버퍼링을 행할수 있는데. cpu는 출력장치가 받아들일때까지 레코드를 생성하여 버퍼에 저장할 수 있다.
cpu는 자신의 일을 수행하고 입출력장치는 채널과 같은 제어장치에 연결되어 제어장치가 cpu와 데이터를 주고받을 수 있다. 이렇게 함으로서 입출력을 cpu와 무관하게 비동기적으로 수행할 수 있다.
보다 효율적인 처리를 위해서 하나의 입력장치, 출력장치에 2개 이상의 버퍼를 사용할 수 있는데, 다중 버퍼가 사용된다면 많은 양의 주기억장치가 버퍼에 할당되어 이용 가능한 주기억장치의 크기가 줄어든다
cpu가 평균적으로 입력장치보다 훨씬 빠르다면 버퍼링은 별 의미가 없다. 입력 버퍼는 언제나 empty 상태에 있게 되므로 cpu는 항상 입력장치를 기다려야 하기 때문이다. 이러한 상황은 입출력 위주 작업 하에서 발생하는데, cpu는 입출력장치보다 속도가 빠르므로 살행속도는 입출력 장치의 속도로 한정된다.
복잡한 계산이 많아서 입력 버퍼는 항상 가득 차 있는 반면, 출력 버퍼는 항상 비어있는 cpu위주 작업의 경우 cpu는 입출력장치보다 속도가 떨어질 수 있다.
결론적으로 버퍼링은 cpu와 입출력장치 간의 속도 차이를 충분하지는 않지만 어느 정도 극복할수 있도록 한다.
## SPOOLing(Simultaneous Peripheral Operation OnLine)
버퍼링은 주기억장치를 버퍼로 사용하는 반면, 스풀링은 디스크를 매우 큰 버퍼처럼 사용하는 것이다.
특히 다중 프로그래밍 환경 하에서, 다수의 프로세스들이 입출력장치를 서로 요구하나, 그 장치의 수가 제한되어 있을때 이들에 대한 공유를 가능하게 하기 위하여 가상장치를 각 프로세스에 제공해 주는 개념
보통 가상 장치들은 스풀링 통제 프로그램에 의해 디스크에 나타나게 되는데, 이것 때문에 다수의 프로세스들은 각기 독립적인 입출력 장치를 가지는 셈이 된다.
프로세스는 입력,출력을 실제 입력 출력 장치를 사용하지 않고, 가상 입출력장치인 디스크를 매체로 이용한 후, 다시 실제의 입력과 출력을 행하도록 한다.
이런 모든 일은 운영체제의 일부인 SPOOL이라는 프로그램이 수행하게 된다.
cpu위주의 작업과 입출력 위주의 작업이 혼합되어 있는 경우, 어느 정도의 디스크 공간과 테이블을 확보함으로서 cpu는 한 작업의 계산과 다른 작업의 입출력을 중복 수행할 수 있고, 작업의 효율도 극대화 할수 있다.
스풀링은 작업 풀(job pool) 이라고 하는 중요한 자료구조 형태를 제공함으로서, 일반적으로 디스크에 읽혀 들여저 대기하고 있는 여러 작업들이 실행될 수 있도록 준비시키고, 운영체제가 다음에 수행한 작업을 선택할 수 있도록 한다.
수행될 작업들이 자기 테이프로부터 들어온다면 순서를 무시하고 다른 순서로 수행할수는 없다. FCFS가 지켜져야 하므로
그러나 여러 작업들이 디스크와 같은 direct access가 가능한 장치에 있다면, 작업은 완급이나 우선순위에 따라 작업 스케줄링이 가능하다.
## channel
cpu와 입출력장치는 속도차이가 있으므로, 직접 연결하는것은 효율적이지 못하다. 사이에 입출력 전담 처리기인 I/O channel을 두어 컴퓨터 시스템을 구성한다.
모든 입출력이 채널을 통하여 수행됨으로서 cpu는 입출력이 실제로 수행 완료될때까지 기다리거나 수시로 입출력장치의 상태를 점검할 필요 없이 계속하여 연산을 수행할 수 있다.
채널은 종류가 다양하여, 간단한 처리기에서부터 cpu와 거의 동일한 것까지 있다. 그러나 입출력을 처리하기 위한 처리기라는 점은 동일하다.
select channel - 여러개의 입출력 장치가 연결되어 있다 하더라도 한번에 단 하나의 입출력장치만을 선택적으로 지원, 비교적 전송 속도가 빠른 입출력장치인 디스크나 CD-ROM등의 입출력을 제어
multiplexer channel - 비교적 전송 속도가 느린 입출력장치를 제어하기 위한 채널, 다수의 저속도 입출력장치가 채널의 단일한 데이터 경로를 공유하면서 데이터를 전송. 여러개의 저속도 입출력장치가 멀티플렉서 채널에 연결되어 시분할(timesharing)형태로 제어된다.
채널과 중앙처리장치 간의 통신은 일반적으로 interrupt에 의해 이루어진다.
중앙처리장치가 입출력 명령을 처리하는 상황에서의 채널의 동작 원리는 이렇다.
## interrupt
인터럽트는 시스템에 예기치 않은 상황이 발생하였을때, 그것을 운영체제에 알리기 위한 매커니즘이다. IBM계열 기계는 원인에 따라 6개 종류가 있다.
### 종류
1. 입출력 인터럽트 - 해당 입출력 하드웨어가 주어진 입출력 동작을 완료하였거나 입출력의 오류 등이 발생하였을때, 중앙처리장치에 대해 요청하는 인터럽트
2. 외부(external) 인터럽트 - 시스템 타이머에서 일정 시간이 만료된 경우나 오퍼레이터가 콘솔 상의 인터럽트 키를 입력한 경우, 또는 다중 처리 시스템에서 다른 처리기로부터 신호가 온 경우, 정전 등 외부적 요인
3. SVC(SuperVisor Call) 인터럽트 - 사용자 프로그램이 수행되는 과정에서 입출력 수행, 기억장치의 할당, 또는 오퍼레이터의 개입요구 등을 위해 실행중의 프로그램이 SVC 명령을 수행하는 경우에 발생(SW인터럽트)
4. 기계검사 인터럽트 - 컴퓨터 자체 내의 기계적인 장애나 오류로 인한 인터럽트(HW인터럽트)
5. 프로그램 에러 인터럽트 - 주로 프로그램 실행 오류로 인해 발생, 0으로 나누거나, 보호되어있는 기억장소에 대한 접근, 허용되지 않는 명령어의 수행, 스택 오버플로 (내부 인터럽트,프로그램 검사 인터럽트)
6. 재시작 인터럽트 - 오퍼레이터가 콘솔상의 재시작 키를 누를떄 일어난다(외부 인터럽트)
### 구조 및 처리
인터럽트는 중앙처리장치가 명령어를 수행하고 있는 동안, 이와 병행적으로 발생하는 상황에 대처하기 위해 필요한 제어 이동을 발생시키는 것을 의미한다.
cpu는 인터럽트 발생 신호를 받으면 PC(프로그램카운터)의 내용과 프로그램 수행 상태에 관한 모든 정보를 저장한 후에, 문제의 해결을 위한 처리과정이 기술된 인터럽트 처리기(interrupt handler)의 시작 주소를 PC로 옮긴다. 그 후 인터럽트 루틴을 수행하여 해당 상황을 처리하면, 인터럽트가 발생하기 이전에 처리하던 프로그램의 수행 과정을 계속한다.
문맥 교환(context switching) - 인터럽트 발생시 운영체제가 일단 인터럽트 된 실행중인 프로그램의 상태를 기억시켜두고 인터럽트 처리 루틴에게 넘기는 작업
문맥교환의 과정에서 PSW(program status word)는 명령문 수행의 순서를 조절하며, 실행중이던 프로그램 상태에 대한 여러가지 정보를 보관한다.
과거의 PSW, 새로운 PSW는 미리 결정된 주기억장소에 위치하고, 인터럽트가 발생하면 현재의 PSW를 과거의 PSW에 저장하고 새로운 PSW를 현재의 PSW에 저장한다.
그 후 cpu는 현재의 PSW에 의해 명시된 명령어를 수행하기 시작한다. 이 과정을 거치는 동안 인터럽트가 처리된다.
인터럽트 처리 루틴의 마지막 부분에는 과거의 PSW를 현재의 PSW로 환원시키는 명령어가 수행된다. 이 명령어를 수행함으로서 시스템은 인터럽트가 발생하기 이전의 상태로 되돌아가 중단되었던 프로그램의 수행을 계속한다.
-----------------------
학교 내용
# 운영체제의 역할
1. 프로세서, io장치, 세컨더리 메모리 관리
2. 서비스 제공
# basic elements
프로세서, io modules, main memory, system bus
# 프로세서
컴퓨터의 operation 제어, data processing
휘발성(volatile)
# io modules
사용자가 입력하면 메인 메모리로 가져와서 처리할 수 있도록 하고, 화면에 보여주는 장치
# system bus
cpu, 메모리, io장치 연결
# 높은 수준에서 추상화 구조
cpu는 PC가 가리키는 instruction을 읽어와서 처리하는 일만 한다.
MAR에 주소를 주고, MBR로 가져와서 처리
io모듈은 버퍼를 가지고 있다. 버퍼는 메모리 거의 같은 취급의
IR : instruction을 저장하는 장치 (명령어 레지스터 - 가장 최근에 인출된 명령어 코드가 저장되어 있는 레지스터)
execution unit : 실행하는 장치
# 마이크로프로세서
cpu를 간단한 칩 위에 집적시키는 기술이 나오면
메인프레임 시스템 > 사람들이 쓸수있는 마이크로프로세서 > 멀티코어프로세서
# GPU
프로세서 여러개 달린 장치. 병렬처리
# DSP
영상, 오디오 처리하는 전용 프로세서
# SoC
휴대폰, 라즈베리파이 같은것. 하나의 컴퓨터를 하나의 칩으로 만든것
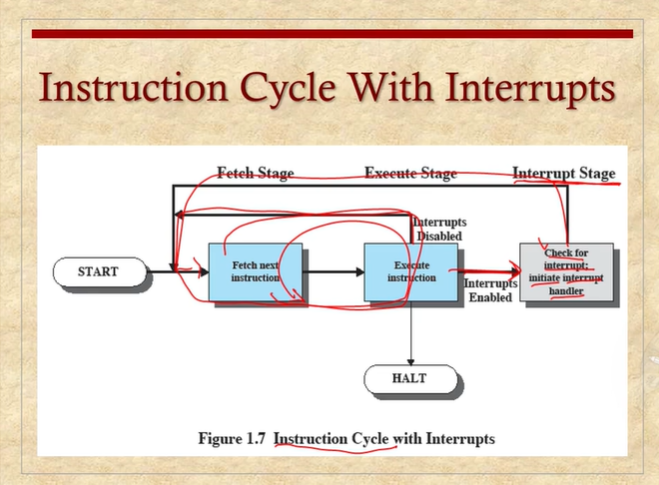
# instruction cycle
# 가상 기계의 instruction format


# interrupt
# 일반적인 instruction cycle에서는
Fetch - execute instruction 반복
여기에 + interrupt
# interrupt 종류 4가지
프로그램 - 연산 오버플로우, divide by 0, 배열 인덱스 에러(array밖)
타이머 - 프로세서에는 타이머가 들어있다. 그때마다 규칙적으로 다른 기능을 할수있도록 함(한 프로그램 돌리다가 다른 프로그램 돌릴수 있도록, 마치 여러 프로그램 돌릴수 있도록)
IO - IO controller에 의해 발생
Hardware Failure - HW에서 발생하는, power failure나 parity error
#
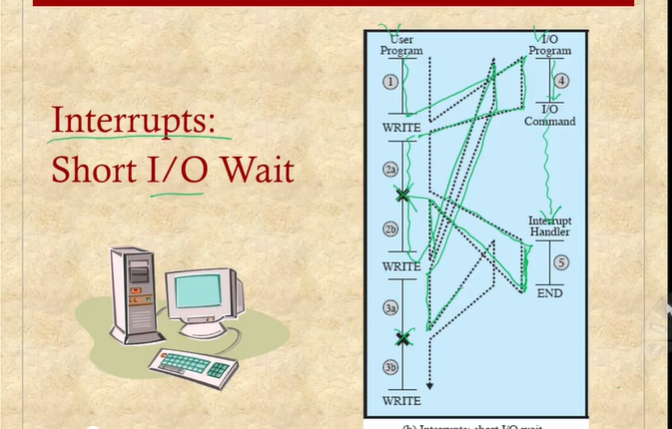
인터럽트는 cpu에 비해 상대적으로 느린 장치에 의해 발생
ex) 인터럽트를 사용해서 디스크가 동작할때마다 cpu에 인터럽트를 걸고, 대부분 프로세서는 계산을 프로그램이 돌리고 있다가. 디스크와 관련된 일을 처리할때는 인터럽트 스테이지에서 처리하도록 만들어놓음
#
인터럽트가 없는 상태에서 프로그램 실행.
cpu는 write에서 다른 일을 할 수 있음에도 정지하고 기다리게 된다. cpu가 자원이 남게됨. 처리하는동안 다른일을 할수 있게 하는것이 인터럽트(비동기적)
다만 마우스 이벤트같은 것이 언제 발생할지 모른다. 모든 경우를 시험할수는 없다.
결국 IO프로그램을 잘 만들어야 한다는 어려움이 있다.
#
유저 프로그램이 있으면 PC가 바뀌어서 interrupt Handler로 점프, 실행되다가 끝나면 돌아와야.
cpu는 레지스터 셋이 하나만 있으므로 IO프로그램이 돌다가 돌아오면 지워진 상태가 된다. cpu에서 돌던 레지스터 셋을 저장할 방법이 필요.
내용을 저장했다가 레지스터를 복구하는것을 조금만 잘못해도 프로그램이 엉망이 될수도
#
인터럽트는 cpu에 인터럽트를 체크하는 스테이지가 따로 있다. instruction cycle중 마지막 스테이지가 interrupt stage (인터럽트를 체크하고, 인터럽트가 HW신호로 들어왔으면, 인터럽트 핸들러를 초기화하는 - reg값 저장, PC값 바꿔서 점프)
Fetch - Execute - 인터럽트 체크 안왔으면 다시 Fetch로 돌아가서 반복하는...
interrupt를 disable 시킬수도 있고, 그러면 안에서만 돌게 된다.
모든 CPU가 그렇게 만들어져 있다.
#
HW로 이루어지는 부분 - 신호를 주는부분부터 PC를 바꾸는 부분까지
SW로 - 처리하고 있던 부분을 저장하고 다시 restore하는 부분, 그리고 interrupt를 처리하는 부분으로 구성됨
HW와 SW가 맞물려서 돌아간다.
<HW에서>
1. 모든 인터럽트 시작은 다른 HW가 인터럽트를 발생하는것에서 시작
2. 기존에 하던 process를 멈추고
3. 잘 받았다고 알려준다
4. process에서 저장해야 할 값(PSW,PC)를 controll stack에 넣는다
5. 인터럽트 서비스 루틴의 주소값으로 PC값 바뀌면 ...
다음 fetch가 되면 PC에 들어간 값이 fetch가 되어 실행되니까
interrupt로 점프가 되어 실행
<SW에서>
6. ...
7. process interrupt하고
8. process 상태 정보 원래 상태로 복구
9. PSW와 PC 복구
#
N 주소값을 가지고 있던중에 interrupt가 걸리면, N까지는 끝난거고
PC는 N+1, N+1을 스택에 넣고, PSW를 general registers에 넣고 (위의 4번)
PC의 시작점을 interrupt 의 시작점인 Y로 바꾸게 된다 (위의 5)
돌아올때는 stack pointer에 T가 들어있는데 general registers값을 원래 reg에 다시 집어넣는다.
PC에 다시 N+1이 오게 집어넣고 fetch하여 돌아오게
여러개의 인터럽트가 발생한다면?
1. 인터럽트 사이클을 중단 disable - 다중 인터럽트가 처리 안되도록
2. 우선순위를 둔다
순차적으로 처리하거나(Sequential), 인터럽트 도중 또 처리해야 할수도 있다.(Nested)
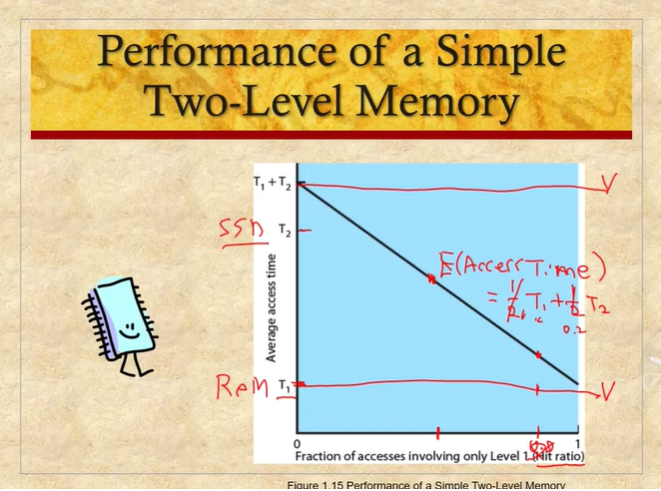
# 메모리 계층
amount, speed, expense
메모리는 계층구조를 가지고 있다.
보조메모리 : 비휘발성, 외부, 영구적 저장 위해 사용
# Principle of Locality 지역성
프로그램은 특정 연산을 집중적(반복적)으로 실행, 나머지는 한번만 실행. data의 접근도 특정 부분에 집중되는 특성이 있다.
locality를 잘 이용하면 저렴한 비용으로 많은 고성능 메모리를 시간측면에서 사용할수 있는 이득이 있다.
#
레지스터 다음으로 있는것이 캐시메모리
cpu에서 접근되는 작은 양의 메모리를 가지고 cpu안에 있던것처럼 계속 쓸수 있게하는 기억장치. OS가 볼수없고 HW가 관리, 성능에 많은 영향.
메인메모리의 일정부분을 가져와서 processor가 데이터에 엑세스할때 먼저 cache를 확인(instruction이건 data건)
모든 프로그램이나 data는 locality가 존재
#
cache는 cpu안에 있다. 인텔은 L3까지. 메인메모리랑은 버스로 연결
#
캐시가 메인메모리에 read하는 과정
cpu가 주소를 발생시키면, cache에 있는지 확인하고 있다면 사용
없다면 메인메모리에 접근, 주변까지 포함하여 cache에 저장하여 사용
가져온것을 cpu에 보내서 사용할수 있게 함
#
가장 최근에 덜 사용된것을 내보내는 알고리즘
# 입출력장치의 프로그램
IO장치의 프로그래밍 방법
프로세서가 입출력과 관련된 instruction과 만나게되면 io장치에게 상태를 알려서 동작할수 있도록 명령을 실행하게 된다
그 방법에는
1. programmed io
프로세서가 모든것을 책임진다. 프로세서가 주기적으로 io의 상태를 검사하여 io를 할수있는지 아닌지 검사하여 직접 io장치를 드라이브해서 io를 하도록 하고, 주기적으로 그것이 이루어지는지 체크를해서 된다면 하던걸 계속하고, 반복적해서 입출력이 이루어지는지 확인
cpu의 관리 통제를 받는 io모듈은 요구받는 행동을 실제로 행하고, 그 결과를 io 스테이터스 레지스터에 설정함으로서 cpu에게 그 사실을 알려주게 된다.
그렇게하면 cpu가 계속 io장치를 통제하게 되고. 굉장히 느린 외부 장치를 cpu가 계속 관리하는 동안 실제로 io가 이루어지는 동안에 시간이 낭비가 된다.
전체 시스템이 굉장히 느려지는 단점이 있음 (속도차이 때문) cpu 입장에서는 바람직하지 못하다.
2. interrupt driven io
cpu는 계속 상태를 확인하는게 아니고 io동작 만큼은 다른 장치(io 컨트롤러, io채널)에게 맡기고 하던 계산을 계속하는것
프로세서는 io 커맨드를 실행 > io모듈이 인터럽트 발생 > 프로세서는 data transfer해서 특정 메모리 블럭 보내줌 > io채널이 일함
cpu가 계산과 입출력을 번갈아가며 수행하는것이 실제 과정. programmed io 보다 효율적이지만 계속해서 프로세서가 일해야 하는 단점.
프로세서가 io에 들어가는 data transfer를 위해 계속 일해야함.
프로세서에 있는 캐시들이 data transfer를 위해 사용되므로 locality 깨짐. (missed and flushed) hit ratio가 급격히 낮아짐, 속도저하
3. DMA(direct memory access)
메인메모리로부터 io장치에 있는 버퍼로 옮기는 일을 위탁
데이터를 버퍼로 옮기거나 io버퍼에서 가져오거나 할때 DMA 장치에 그 일을 위탁
read인지 write인지
io디바이스 어디에 옮겨갈지
메모리 어디부터 옮겨갈지. source와 destination목적지 두 주소를 주게 되고
몇개의 워드, 바이트를 읽고 쓸건지
이 값들을 주고 일을 위탁.
데이터의 블록을 한꺼번에 IO컨트롤러와 메모리에 옮기는데 프로세서의 관여가 필요 없다.
프로세서는 시작과 끝에만 관여. 중간에는 관여하지 않음. 그 동안에는 계산할수 있게 된다.
# 멀티프로세서
#SMP
지금쓰는 노트북같은것. 2개 이상의 프로세서, 프로세서는 메인메모리를 공유, 버스에도 연결되어있고 모든 장치에 접근가능 io장치도 가능. 프로세서는 동일한 일을 하게되는데. 이건 os가 관리하여 사용자가 일을 빨리 실행할수 있도록 os가 기능을 제공
성능 향상
프로세서를 붙일수록 더 빨라짐 (i7,i9 ...)
어떤 코어가 고장나더라도 나머지 코어로 사용가능 availability. 서버같은 경우
# 멀티코어컴퓨터
마이크로프로세서에 여러개의 코어가 들어간것
하나의 실리콘 다이에 여러개가 올라감. 각각은 독립적으로 움직이는 컴퓨터
보통 L2캐시는 각각. L3은 공통으로 쓴다
인텔 i7
#요약









































Comments 0